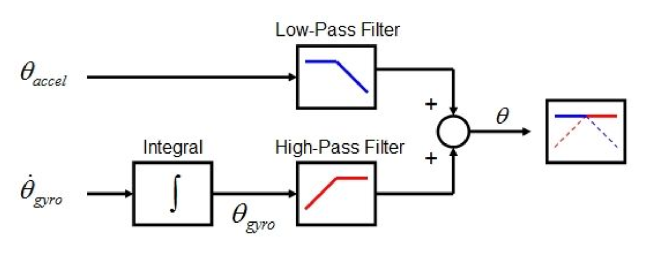
A reoccurring problem in computer vision has to do with finding the precise location of an object in the image. In this post, I want to discuss specifically the problem of finding the location of a blob or a point in an image. This is what you’d get when a light source is imaged.
Finding the center of the blob is a question I love asking in job interviews. It’s simple, can be solved with good intuition and without prior knowledge, and it shows a lot about how one grasps the process of image formation.
What’s a blob?
A blob is what’s formed on an image plane when imaging a light source. For instance, here’s how you might imagine a set of LEDs would appear in an image:

This is interesting problem because if we know the location of the center of each blob, and if we know the 3D pattern that generated it (eg. the 3D shape of the LED array) then we can reconstruct its position in 3D space.
There are many possible approaches here. Most of them are either too expensive computationally, unnecessarily complex or plainly inaccurate. Let’s discuss a few:
I) Averaging
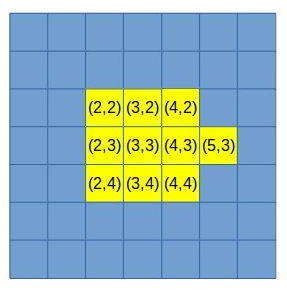
This one is rather simple. We take all the pixels associated with a blob and find their average. Here are two examples:
Computing the average of all pixels above would give us x=3 and y=3 as the sum of all x coordinates and all y coordinates is 27 and there are 9 pixels.
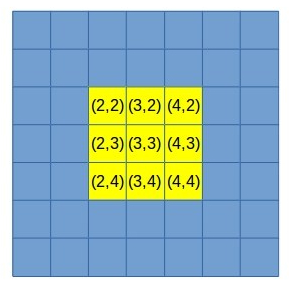
Here, however, the average is different. Now the average x is 3.2 and the average y is still 3. This isn’t surprising — the center is shifting to the right because of the additional pixel.
This computation is simple and require very little computation. However, it’s obviously not very precise. We can easily see that our average is in the space of 1/2 pixel — the center either lands on a pixel center or its edge (between two pixels). This is terrible accuracy for 3D reconstruction (unless you have a super narrow field of view and/or extremely high resolution image sensor).
But wait, it gets worse. This method doesn’t take into account the brightness of pixels. For example, imagine pixel (5,3) above was extremely dim. So dim, in fact, that it would be just on the threshold of our image sensor. The result will be that the pixel would appear or disappear in consecutive frames due to image noise. The center of the blob will be greatly effected by this phenomena. Not good.
II) Circle Fit
How about fitting a circle to the blob? It seems like this would give us much higher precision and aren’t circles pretty robust to noise?
Well yes in theory but not so much in practice.
First, let’s consider the image of even a really small light source. The light source isn’t going to be a point source in practice. We can imagine it has some small circular shape. But, when that light source gets projected onto the image plane, the result is an ellipse and not a circle. Fitting an ellipse is much more complex and less robust than circle fit.
Second, the image formation process is unlikely to result in pixels that are all saturated. We are going to get shades of white as the distance from the true center increases. Here’s an example:

As can be seen in the image, pixels have less brightness when further out from the blob center. In fact, pixels at the edge of the blob might not always pass the sensor’s threshold and remain black. These pixels are going to have a significant impact on the fit.
And finally, in many cases blobs are going to be pretty small. Circle fit is much less robust with fewer pixels.
Weighted Average
A weighted average is almost as simple as the averaging method discussed above. However, it takes into account the strength of the signal in each pixel and it doesn’t assume the projected shape is a circle. Weighted average takes the brightness level of each pixel, and uses it as a weight for the average.
Now, imagine the 2nd example above, where all pixels have brightness level of 255, except for pixel (5,3) that is very dim, say brightness level of 10. Now, our weighted average will yield: x = 3.008 while y remains 3. This makes perfect sense: the dim pixel is pulling the center only slightly towards it. If that pixel was brighter, the pull would be stronger and the computed center will shift towards it.
Weighted average is also a great way to eliminate noise in the image. It’s simple, precise and much more robust.
Summary
I’ve used this method to solve multiple computer vision problems over time. Check out my patents page. Some of them use a version of this technique.