Image processing was for a long time focused on analyzing individual images. With early success and more compute power, researchers began looking into videos and 3D reconstruction of the world. This post will focus on 3D. There are many ways to get depth from visual data, I’ll discuss the most popular categories.
There are many dimensions to compare 3D sensing designs. These include compute, power consumption, manufacturing cost, accuracy and precision, weight, and whether the system is passive or active. For each design choice below, we’ll discuss these dimensions.
Prior Knowledge
The most basic technique for depth reconstruction is having prior knowledge. In a previous post (Position Tracking for Virtual Reality), I showed how this can be done for a Virtual Reality headset. The main idea is simple: if we know the shape of an object, we know what its projected image will look like at a fixed distance. Therefore, if we have the projected image of a known object, it’s straightforward to determine its distance from the camera.
This technique might not seem very important at first glance. However, keep in mind how good people are at estimating distance with one eye shut. The reason for that is our incredible amount of prior knowledge about the world around us. If we are building robots that perform many tasks, it’s reasonable to expect them to build models of the world over time. These models would make 3D vision easier than starting from scratch every time.
But, what if we don’t have any prior knowledge? Following are several techniques and sensor categories that are suitable for unknown objects.
Stereo
Stereo vision is about using two camera to reconstruct depth. The key is knowledge of the calibration of the cameras (intrinsics) and between the cameras (extrinsics). With calibration, when we view a point in both cameras, we can determine its distance using simple geometry.
Here’s an illustration of imaging a point (x,y,z) by two cameras with a known baseline:
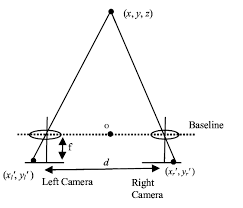
We don’t know the coordinate z of the point, but we do know where it gets projected on the plane of each camera. This gives us a ray starting at the plane of each camera with known angles. We also know the distance between the two projection points. What remain is determining where the two rays intersect.
It’s worth noting that to compute the ray’s angle we need to know the intrinsics of the camera, and specifically the focal length
Stereo vision is intuitive and simple. Image sensors are getting cheaper while resolution is going up. And, stereo vision has a lot in common with human vision, which means our systems can see exactly when people expect to see. And finally, stereo systems are passive — they don’t emit a signal into the environment — which makes them easier to build and energetically efficient.
But, stereo system isn’t a silver bullet. First, matching points/features between the two views can be computationally expensive and not very reliable. Second, some surfaces either don’t have features (white walls, shiny silver spoon, …) or have many features that are indistinguishable from each other. And finally, stereo doesn’t work when it’s too dark or too bright.
Structure from Motion
Structure from motion replace the fixed second camera in the stereo design with a single moving camera. The idea here is that as the camera is moving around the world, we can use views from two different perspectives to reconstruct depth much like we did in the stereo case.
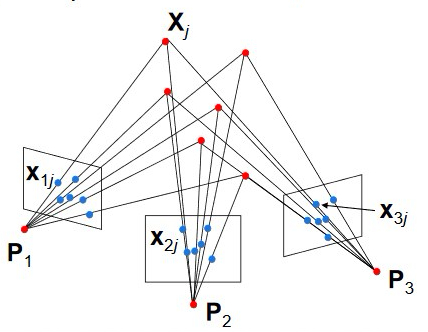
Now’s a great time to say: “wait what?! didn’t you say stereo requires knowledge of the extrinsics?”. Great question! Structure from motion is more difficult in that we not only want to determine the depth of a point, but we also need to compute the camera motion. And no, it’s not an impossible problem to solve.
The key realization is that as the camera is moving, we can try to match many points between two views, not just one. We can assume that most points are part of the static environment (ie. not moving as well). Our camera motion model therefore must provide a consistent explanation for all points. Furthermore, with structure from motion we can easily obtain multiple perspectives (not just two like stereo).
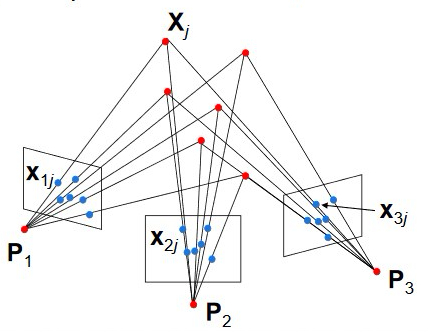
Structure from motion can be understood as a large optimization problem where we have N points in k frames and we’re trying to determine 6*(k-1) camera motion parameters and N depth values for our points from N*k observations. It’s easy to see how with enough points this problem quickly becomes over constrained and therefore very robust. For example, in the above image N=6 and k=3: we need to solve a system of 18 equations with 18 unknown.
The key advantages of structure from motion vs. stereo include simple hardware (just one camera), simple calibration (we only need intrinsics), and simple point matching (because we can rely on tracking frame-to-frame).
There are two main disadvantages. First, structure from motion is more complex mathematically. Second, structure from motion provides us a 3D reconstruction up to a scaling parameter. That is, we can always multiply the depth of all our points by some number and similarly multiply the camera’s motion and everything remains consistent. In stereo, this scaling ambiguity is solved through calibration: we know the baseline between the two cameras.
Structure from motion is typically solved as either an optimization problem (eg. bundle adjustment) or a filtering problem (eg. extended Kalman filter). It’s also quite common to mix the two: use bundle adjustment at a lower frequency and the Kalman filter at the measurement frequency (high).
3D Sensors
There are several technologies that try to measure depth directly. In contrast with the above methods, the goal is to recover depth from a single frame. Let’s discuss the most prominent technologies:
Active Stereo
We already know the advantages and disadvantages of stereoscopic vision. But what if our hardware could make some disadvantages go away?
In active stereo systems such as https://realsense.intel.com/stereo/ a noisy infra red pattern is projected on the environment. The system doesn’t know anything about the pattern, but its existence creates lots of features for stereo matching.
In addition, stereo matching is computed in hardware, making it faster and eliminates the processing burden on the host.
However, as its name implies, active stereo is an active sensor. Projecting the IR pattern requires additional power and imposes limitations on range. The addition of a projector also makes the system more complex and expensive to manufacture.
Structured Light
Structured light shares some similarities with active stereo. Here too a pattern is projected. However, in structured light a known pattern is projected onto the scene. Knowledge of how the pattern deforms when hitting surfaces enables depth reconstruction.
Typical structured light sensors (eg. PrimtSense) project infra red light and have no impact on the visible range. That is, humans cannot see the pattern, and other computer vision tasks are not impacted.

The advantages of structured light are that depth can be computed in a single frame using only one camera. The known pattern enable algorithmic shortcuts and results in accuracy and precise depth reconstruction.
Structured light, however, has some disadvantages: the system complexity increases because of the projector, computation is expensive and typically requires hardware acceleration, and infra red interference is possible.
Time of Flight
Time of flight sensors derive their name from the physics behind the device. It relies on the known time it takes an infrared beam to travel a distance through a known medium (eg. air). The sensor emits a light beam and measures the time it takes for the light to return to the sensor from different surfaces in the scene.
Kinect One is an example of such sensor:

Time of Flight sensors are more expensive to manufacture and require careful calibration. They also have a higher power consumption compared to the other technologies.
However, time of flight sensors do all depth computation on chip. That is, every pixel measures the time of flight and returns a computed depth. There is practically no computational impact on the host system.
Summary
We reviewed different technologies for depth reconstruction. It’s obvious that each has advantages and disadvantages. Ultimately, if you are designing a system requiring depth, you’re going to have to make the right trade-offs for your setup.
A typical set of parameters to consider when choosing your solution is SWaP-C (Size, Weight, Power and Cost). Early on, it’s often better to choose a simple HW solution that requires significant computation and power. As your algorithmic solution stabilizes, it is easy to correct SWaP-C later on with dedicated hardware.